OK, so last time we looked at sampling. How does all this differ to modelling? Well, lets have a look;
OK, so last time we looked at sampling. How does all this differ to modelling? Well, lets have a look;
The idea of physical sound modelling has been around since the early 1970’s. The principal is very simple – any sound can be approximated by adding other sounds (or waveforms) together. The more sounds you add together, the more complex and (if the individual sounds/waveforms are correct) realistic is the final result.
Take a drum. If you could isolate the sound of the top head, the bottom head, the shell, the room and any other factor (snare wires etc) and put them back together, you’d have a very good representation of the original drum sound.
Physical modelling also works around strict rules. We know that a drum sound decays (or gets quieter) after it is hit, so all parts of a drum sound must get quieter over time. Top head hits also get darker as the impact of the stick loses energy (or, to recreate that, have a filter sweep on them), but bottom heads don’t to the same degree (although they don’t have the stick attack that the top head does…). Maybe a birch shell resonates for a shorter amount of time than a maple shell. Maybe a birch shell’s sound has less mid range frequencies. All these factors (and loads, loads more) must be taken into account for a truly accurate sound to be reproduced. So modelling predicts what a sound will be like by using information it knows and assumptions it takes.
To make each separate part of each sound or waveform, synthesis is used. This means the correct waveforms are created in a synthesizer program in a computer, are mixed together and (hopefully) sound like the sound you were hoping for.
Now is a good time to mention that if you have a modelling module and you see ‘Bubinga tom’ or ‘Maple snare’, you aren’t actually getting the sound of that drum. When the manufacturers create the sounds for a modelled module, they sample sounds (which is where the confusion comes from about modelled modules containing samples), and then the sample is forensically analysed by human ear and computer to work out the best way of recreating it, but (generally) none of the original source sound is used in the modelled one.
So what you are getting is a computers most accurate and processor-effective way of recreating that sound by adding (essentially) sine waves together in exactly the right proportions, and adhering to the strict rules of what makes a drum sound like a drum.
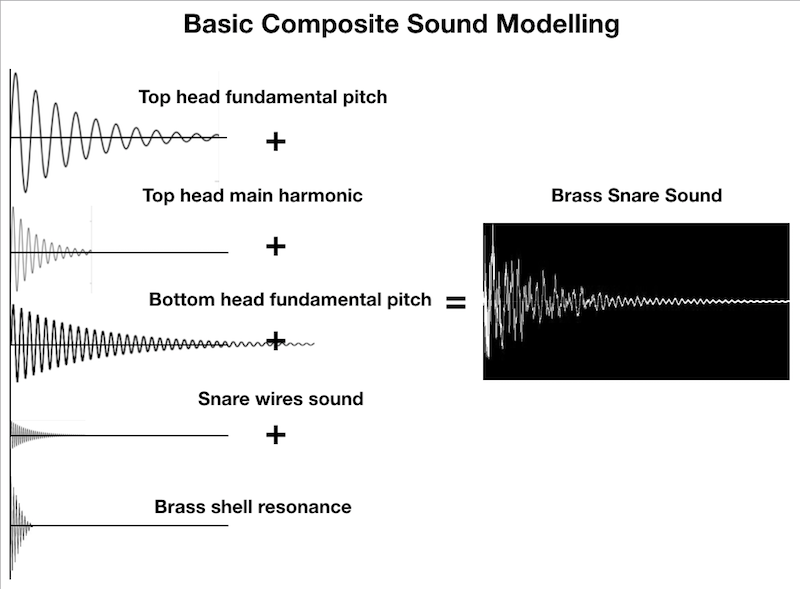 Many drum modelling systems use around eight layers, or elements, to recreate each drum sound – the top head fundamental pitch, the top head main overtone and secondary overtone, the bottom head fundamental and overtone pitch, the shell sound etc etc. Added to this is snare buzz if required, room sound and anything else which is deemed essential. Put it all in the mix and Voila… your unique drum sound.
Many drum modelling systems use around eight layers, or elements, to recreate each drum sound – the top head fundamental pitch, the top head main overtone and secondary overtone, the bottom head fundamental and overtone pitch, the shell sound etc etc. Added to this is snare buzz if required, room sound and anything else which is deemed essential. Put it all in the mix and Voila… your unique drum sound.
Add to that some EQ and theoretically you have the most flexible drum sound in the world. If you want to hear what the raw modelled sound is really like, just turn off the reverb (which helps to give the sound ‘life’), and any ‘additions’ such as snares or effects, and you have the raw modelled sound.
So in your modelled drum module is a reference bank of modelled waveforms (but not audio samples) which the module draws from to create whatever sound is required. Using lots of clever maths, the waveforms are mixed together to create the required sound.
If you really want to look more into this, I really recommend this work from Stanford University (who incidentally worked with Yamaha to develop the original instrument modelling data for the first modelling synthesizer, the VL1 in1994)
https://ccrma.stanford.edu/~jos/pasp/
What makes one better than the other?
Now what makes drum sound modelling very good is that it is very easy to alter the sound without distorting it as the module has access to each separate part/component of the sound. Want to detune the bottom head? Easy – just turn down the pitch of the bottom head fundamental and overtone. Want to pitch the whole drum sound up? Easy – just turn up the pitch of all tuned elements (top head and bottom head frequencies). Make the drum bigger? Pitch down the shell element and head pitches proportionally. And all this you can’t do on a sample.
If you try and pitch a sample up too high or too low, you get ‘aliasing’ where unwanted elements appear in the sound and it begins to sound fake (think of the chipmunk effect if you pitch your voice up). Aliasing is also what makes low res MP3s and YouTube videos sound rubbish and ‘phasey’. What samples are excellent for are recreating a perfect moment in time when the original drum that was sampled sounded fantastic in the studio. Its why one current drum module doesn’t allow you to change the pitch of the sounds – to do so would add aliasing to the sound (albeit very subtly) and this would compromise the sound quality.

The first modelling synth – the Yamaha VL1
However, modelling is far from perfect too – if modelling WAS perfect we’d hear it on every single record in the charts and everybody would gig electronic kits… and we all know that doesn’t happen.
This is because modelling is never 100% accurate. This is because to make a 100% accurate drum sound would require an infinite amount of layers or elements. When all modelling modules use a minute percentage of that (can you even have a percentage of infinity?), then it will never reach perfection.
To my ears (and I’m going to lay my position on the table here), modelling has a distinctive sound when it is recreating acoustic drum sounds, which is very recognisable if you know what you are listening for. It works for modelled pianos and guitar effects, but, for me, just not drums, and I can explain exactly why. It is ‘too good’, in other words it sounds too clean and perfect. A digital recording or sample of a drum can capture the imperfect sound of the badly built American classic tom with the dodgy gum ply in the middle of the shell and the loose lug on the bottom head, which is what gives that particular drum its character. And that is exactly what I think is missing in modelled sounds – character – and until there is a ‘character’ knob to turn up on a modelled module (which, lets face it, may be just around the corner), it isn’t for me.
But modelling is perfect for making elastic drum sounds which can be tuned up, down, stretched in impossible (in the real world) ways for unique drum sounds. Swedish Death Metal would be rather different without modelled drum sounds as they are perfect for that style of music – clinical, perfect, cutting. Modelling is also (weirdly) perfect for recreating electronic sounds which were synthesised in the first place. A model of an 808 cowbell is always much nicer and more useable than an original 808. I know some will find that sacrilegious, but sorry, thats how I feel!
The other strange thing about modelling and sampling is they sound totally different when they are by themselves to when they are being played with other instruments. I’ve heard (very obvious samples) which didn’t sound great when they were solo’ed, but sounded great in the mix, and I’ve heard modelled sounds which sounded fine by themselves but suddenly sounded fake when they were played with acoustic instruments. It’s weird how the human ear picks up different things in different situations.
So thats our two main sound creation methods. Neither are perfect – both have limitations, and both change the sound in ways which can easily be noticed if you know what you are listening for. But we rely on these methods for our edrums. However, depending on what style of music you play, you might want to look at which method will serve you better for the sounds you need to do your job well.
Simon Edgoose
August 2018
simon@edruminfo.com